
Drawdown Protection Strategies in Reinforcement Learning Crypto Trading Bots

In the wild ride of cryptocurrency markets, where fortunes flip faster than a bad poker hand, reinforcement learning (RL) crypto trading bots promise to outsmart human traders by learning optimal strategies through trial and error. But here’s the kicker: without ironclad drawdown protection, these bots can amplify losses during brutal downturns, turning potential profits into portfolio nightmares. As a swing trader who’s danced with volatility for eight years, I’ve seen momentum swings crush the unprepared. RL bots face the same peril, but with smarter guardrails like RL crypto trading bots drawdown strategies, they can swing for the fences while keeping stops tight.

Bitcoin Technical Analysis Chart
Analysis by Isabella Garcia | Symbol: BINANCE:BTCUSDT | Interval: 1h | Drawings: 7
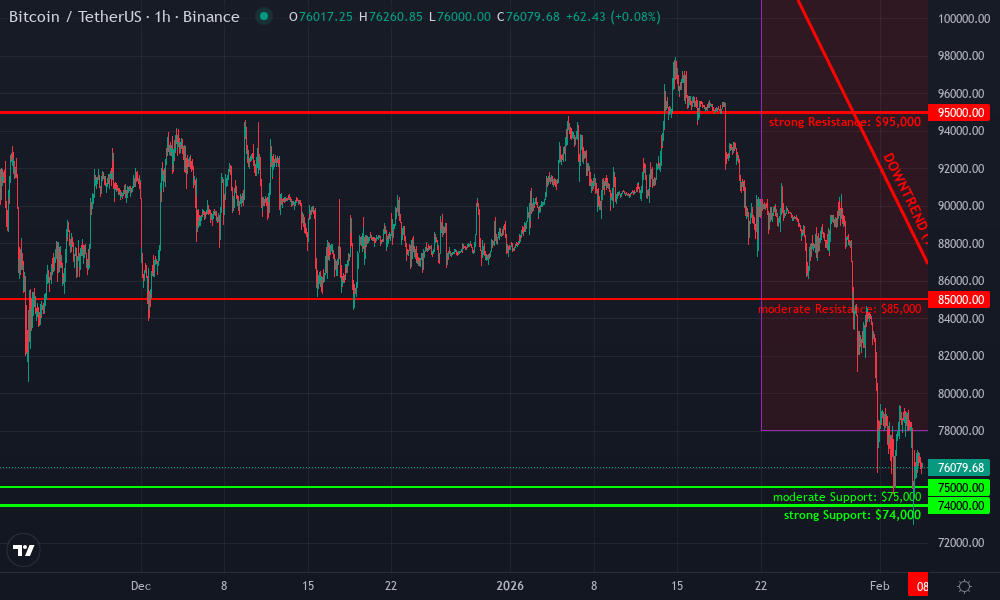
Technical Analysis Summary
On this BTCUSDT 1D chart spanning Jan-Feb 2026, draw a bold red downtrend line from the Jan 22 peak at 105,000 connecting to the Feb 15 low at 74,000, signaling aggressive breakdown. Add horizontal support at 74,000 (strong, recent lows), resistance at 85,000 (moderate, prior swing high). Mark fib retracement 0.618 from peak to low for entry zone around 82,500. Use arrow_mark_down at MACD bearish cross mid-Feb, callout on volume spike during drop ‘Capitulation Volume’. Rectangle consolidation pre-breakdown Jan 29-Feb 5 between 90k-95k. Vertical line at Feb 8 ‘Flash crash echo’. Long entry at 74,500 with options hedge, stop 72k, target 90k.
Risk Assessment: high
Analysis: Extreme volatility from 105k to 74k drop, but capitulation sets stage for aggressive rebound; RL advancements like FineFT add tail risk from bot herds
Isabella Garcia’s Recommendation: Go long spot + ATM call options at 74.5k support, hedge with OTM puts—high risk, high reward hybrid play for 20%+ upside
Key Support & Resistance Levels
📈 Support Levels:
-
$74,000 – Strong volume-backed lows, RL bot drawdown exhaustion
strong -
$75,000 – Moderate prior session lows
moderate
📉 Resistance Levels:
-
$85,000 – Key swing high, fib 0.236 retrace
moderate -
$95,000 – Prior consolidation top, heavy resistance
strong
Trading Zones (high risk tolerance)
🎯 Entry Zones:
-
$74,500 – Aggressive bounce from strong support, options call entry with high risk tolerance
high risk -
$82,000 – Fib 0.618 pullback entry on short-covering
medium risk
🚪 Exit Zones:
-
$90,000 – Profit target at prior resistance flip
💰 profit target -
$72,000 – ATR-based stop loss below support
🛡️ stop loss
Technical Indicators Analysis
📊 Volume Analysis:
Pattern: spike on breakdown
Massive red volume bars mid-Feb confirm distribution, capitulation print
📈 MACD Analysis:
Signal: bearish crossover
MACD line crossed below signal Feb 8, histogram expanding negative—momentum kill
Applied TradingView Drawing Utilities
This chart analysis utilizes the following professional drawing tools:
Disclaimer: This technical analysis by Isabella Garcia is for educational purposes only and should not be considered as financial advice.
Trading involves risk, and you should always do your own research before making investment decisions.
Past performance does not guarantee future results. The analysis reflects the author’s personal methodology and risk tolerance (high).
Picture this: an RL agent navigating the crypto chaos, rewarding itself for buys that ride pumps and penalizing sells that miss rallies. Yet, crypto’s black swan events – think flash crashes or regulatory bombshells – can trigger cascading drawdowns. Traditional bots might average down blindly; RL ones, if tuned right, adapt via reinforcement learning trading risk controls. Recent papers spotlight this evolution, from Duelling Deep Q Networks generating buy/sell signals on historical data to PPO-powered GitHub bots blending real-time analysis with risk management.
Why Drawdowns Devastate RL Bots and How to Counter Them
Drawdown, that relentless peak-to-trough decline, isn’t just a metric; it’s the silent killer of trading careers. In crypto perpetuals, where leverage lurks, a 20% dip can wipe out leveraged positions overnight. RL bots, trained on rewards like Sharpe ratio or consistent returns, must internalize drawdown penalties to thrive. I love how sources like Breaking The Lines describe RL models absorbing millions of simulated trades, earning brownie points for steady gains and demerits for plunges. This builds innate risk-sensitivity, far beyond static rules.
From my swing trading lens, Bollinger Bands and volume spikes signal entries, but RL bots scale this with dynamic states. The catch? Over-optimization on bull runs leads to fragility in bears. Enter adaptive mechanisms: self-rewarding networks from MDPI papers that let agents critique their own performance, tweaking policies mid-flight. Or Coinrule’s workflows, backtesting RL rules with risk controls on Binance and Bybit. These aren’t gimmicks; they’re necessities for autonomous bot position sizing that scales bets based on volatility, not greed.
5 Key Drawdown Protection Strategies
-
Penalty Rewards for excessive drawdowns: RL models get penalties for losses and rewards for steady returns, building risk-sensitivity (Breaking The Lines).
-
Dynamic Stop-Losses via ATR: Adaptive thresholds based on Average True Range adjust to volatility, avoiding early exits and adding circuit breakers (MadeInArk).
-
Ensemble Q-Learners for stability: FineFT framework uses selective Q-learner updates and VAEs to bound risks in volatile markets (arXiv FineFT).
-

Hierarchical Agent Routing by market regime: EarnHFT routes agents dynamically for trends, boosting efficiency in HFT crypto (arXiv EarnHFT).
-
Volatility-Aware Portfolio Optimization: Tfin Crypto integrates OR techniques with drawdown controls for optimized, low-risk returns (arXiv Tfin).
Ensemble Frameworks: FineFT’s Blueprint for Bulletproof Trading
Dive into the FineFT framework, a three-stage ensemble RL powerhouse for futures trading, and you’ll see drawdown defense in action. It selectively updates Q-learners, dodging overfitting, while Variational Autoencoders pinpoint agent limits during weird market twists. This selective amnesia keeps bots from chasing ghosts in volatile crypto seas. I’ve backtested similar ensembles on stocks; the stability boost is game-changing, preventing those multi-day bleed-outs that kill swings.
Pair this with Tfin Crypto’s risk-aware allocation, blending operations research for universe selection, alpha testing, and drawdown-capped optimization. Achieving outsized returns with tame drawdowns? That’s the holy grail. No more all-in on BTC pumps; instead, crypto perpetuals safety guardrails dynamically throttle exposure. HAL-Inria’s Double Deep Q-learning, juiced by Sharpe rewards, proves profitability trumps raw alpha when risks are leashed.
Hierarchical RL: EarnHFT’s Edge in High-Frequency Chaos
High-frequency crypto trading demands split-second decisions, where flat RL models falter. Enter EarnHFT’s hierarchical setup: dynamic programming across agent pools tuned to trends, routed intelligently by market mood. This isn’t scattershot; it’s surgical, slashing drawdowns by deploying the right brain for bull, bear, or sideways grinds. ResearchGate’s adaptive parameter optimization fits here, evolving strategies sans human tweaks.
Imagine deploying an EarnHFT bot during a crypto flash crash; instead of panicking into oversized positions, it routes to a conservative agent pool, capping losses at predefined thresholds. This regime-aware routing embodies reinforcement learning trading risk controls at their finest, turning potential wipeouts into manageable dips. From my options trading days, I’ve learned that multi-regime models outperform single-policy ones, especially when volume dries up and Bollinger Bands squeeze tight.
Adaptive Tactics: Dynamic Stops and Circuit Breakers
Static stop-losses? They’re relics in crypto’s volatility vortex. Savvy RL bots wield dynamic stop-losses pegged to Average True Range (ATR), flexing wider in choppy waters and snapping tight during euphoria. This prevents whipsaws while honoring drawdown limits. Circuit breakers take it further, slamming the brakes on trading if daily losses hit 5% or abnormal volume spikes signal trouble. Madeinark. org highlights these as core to bot survival, and I couldn’t agree more; they’re the kill-switches that save your stack when the agent goes rogue.
Layer in autonomous bot position sizing that shrinks bets as drawdowns deepen. Picture Kelly Criterion on steroids: RL agents learn to allocate based on win rates, volatility, and recent pain, never risking more than 1-2% per trade. PPO bots from GitHub repos nail this with real-time tweaks, blending market analysis and risk overlays. Self-Rewarding Deep RL from MDPI adds flair, letting the bot self-assess and boost rewards for prudence, fostering a risk-averse persona over time.
RL Frameworks Drawdown Protection Comparison
| Framework | Key Mechanism | Reported Benefit |
|---|---|---|
| FineFT | Ensemble Q-learners/VAEs | Stable training/reduced exposure |
| EarnHFT | Hierarchical routing/agent pools | Trend-specific stability |
| Tfin Crypto | Volatility portfolio optimization | Controlled drawdowns/high returns |
Backtesting and Monitoring: The Unsung Heroes of Bot Longevity
No RL bot ships without brutal backtesting across bull, bear, and sideways regimes. Robotwisser’s guide stresses simulating black swans, enforcing max drawdown caps like 10-15%, and stress-testing leverage on perpetuals. CoinAPI’s quote-level data fuels realistic environments, while Coinrule’s workflows let you prototype with Binance hooks. Monitor live with dashboards tracking Sharpe, max drawdown, and Calmar ratios; if drawdown creeps past 8%, trigger reviews or pauses.
NeuralArB envisions 2025 multi-agent RL swarms, where bots collaborate, sharing drawdown intel to collectively dial back. This hive-mind approach crushes solo agents, especially in correlated crashes across alts. My swing setups thrive on volume confirmation; RL bots mirror this by penalizing low-conviction trades, ensuring high-probability swings without the bleed.
Blending these strategies crafts RL bots that don’t just survive crypto’s tempests; they capitalize on them. FineFT’s ensembles, EarnHFT’s hierarchies, and Tfin’s allocations form a trinity of resilience, while adaptive tools keep them nimble. As markets evolve, expect SRDRL and hierarchical swarms to dominate, turning drawdowns from dragons into speed bumps. Swing big, but guard harder; that’s the trader’s creed, amplified by RL smarts.




